R-CNN
任务介绍
目标检测(Object Detection) 将目标的分割和识别合二为一,通俗点说就是给定一张图片要精确的定位到物体所在位置,并完成对物体类别的识别。

输入:image
输出:类别标签(Category label);位置(最小外接矩形 / Bounding Box)
模型架构
R-CNN的全称是Region-CNN (区域卷积神经网络),是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。
按分类问题对待可分为两个模块:
- 模块一:提取物体区域(Region proposal)
- 模块二:对区域进行分类识别(Classification)
能够生成候选区域的方法很多,比如:
objectness
selective search
category-independen object proposals
constrained parametric min-cuts(CPMC)
multi-scale combinatorial grouping
Ciresan
R-CNN 采用的是 Selective Search 算法。
主要难度: 在提取区域上需要面临 不同位置,不同尺寸,提取数量很多的问题。在分类识别方面主要面对CNN分类及计算量大的问题。
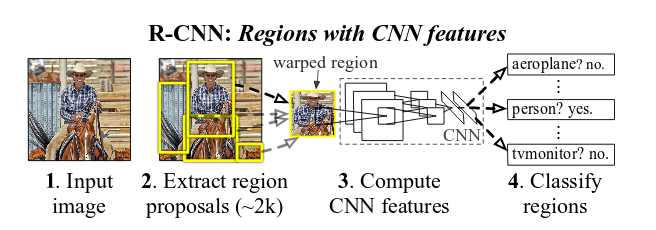
主要流程
R-CNN的步骤如下:
-
图像输入
输入待检测的图像。
-
区域建议(Region proposals)
对第一步输入的图像进行区域框的选取。常用的方法是Selective Search EdgeBox,主要是利用图像的边缘、纹理、色彩、颜色变化等信息在图像中选取2000个可能存在包含物体的区域(这一步骤 选择可能存在物体的区域,跟分类无关 ,包含一个物体)。
- 特征提取
使用CNN网络对选取的2000存在物体的潜在区域进行特征提取。但是可能存在一些问题,由于上一步Region proposals所提取出来的图像的尺寸大小是不一样的,我们需要卷积后输出的特征尺度是一样的,所以要将Region proposals选取的区域进行一定的缩放处理(warped region)成统一的227x227的大小,再送到CNN中特征提取。R-CNN特征提取用的网络是对ImageNet上的AlexNet(AlexNet网络详解)的CNN模型进行pre-train(以下有解释,可先行了解pre-train)得到的基本的网络模型。然后需要对网络进行fine-tune,这时网络结构需要一些修改,因为AlexNet是对1000个物体分类,fc7输出为1000,因此我们需要改为(class + 1)若类别数为20则应改为20+1=21个节点,加一的原因是对图像背景类识别,判断是不是背景。其他的都用AlexNet的网络结构fine-tune(全连接),其中包括五层卷积和两层全连接层。 (在这里使用的是ImageNet竞赛上面训练好的AlexNet模型去除最后两层全连接层的模型(也可以是VGG,GoogLeNet,ResNet等)。特征提取用的是卷积神经网络代替了传统的HOG特征,Haar特征等取特征的方法。)
- SVM分类
将提取出来的特征送入SVM分类器得到分类模型,在这里每个类别对应一个SVM分类器,如果有20个类别,则会有20SVM分类器。对于每个类别的分类器只需要判断是不是这个类别的,如果同时多个结果为Positive则选择概率之最高的。
- Bounding Box Regression
这个回归模型主要是用来修正由第二步Region proposals得到的图像区域。同第四步的分类一样,每个类别对应一个Regression模型。这个Bounding Box Regression主要是为了精准定位。它所做的就是把旧的区域重新映射到新的区域。
- 使用非极大值抑制输出(针对于测试阶段)
可能几个区域选择的是同一个区域内的物体,为了获得无冗余的区域子集。通过使用非极大值抑制(loU>=0.5)获取无冗余的区域子集。主要有以下几步:
-
- 所与区域分值从大到小排列
-
- 剔除冗余,与最大分值区域loU>=0.5的所有区域
-
- 保留最大分值区域,剩余区域作为新的候选集